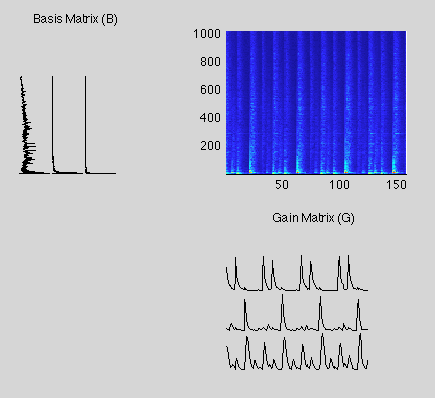
In much the same way that we can factor a number into it's constituent factors (6 = 2 x 3), we can factorize a matrix into two constituent matrices (V = GW, where V, W, and H are all matrices). In this representation, V represents the spectrogram of the input audio, W represents a set of N stationary spectra (spectra is pretty much the FFT), and H represents a set of N volume envelopes (Where N is the number of sources/drums/instrument types present in the recording). Each of the spectra in W is related to a particular volume envelope in H. The combination of a spectra and its corresponding volume envelope represents a single source/drum/instrument. The image below shows the result of a factorization where N = 3. The spectrogram in the upper right is V, the Basis Matrix is W, and the Gain Matrix is H. The first row of the Gain Matrix is the volume envelope for the bass drum, the second row is the volume envelope for a snare drum, and the third row is the volume envelope for a hi-hat (note the wide-band nature of it's spectra in the corresponding Basis Matrix column).
The 'Non-Negative' bit comes from the constraint that no element in V, W or H may be negative. In other words, we can only add up bits of sound, we can not subtract bits of sound in our factorization. The nice bit about this constraint is that it encourages the factorization to be parts-based.
If you're more interested in the mathematics behind NMF, Tuomas Virtanen is a bit of an NMF expert and he has a number of quite nice papers on the subject as it applies to Audio.
There are a number of nice MATLAB implementations of NMF available, chiefly - it seems - because MATLAB comes with all of the necessary data structures and algorithms to easily deal with matrices. C++ is well suited for matrix manipulations, but not out of the box. I'm not a terribly experienced C programmer, but after a bit of research, it seems like the best available options for matrix mathematics are BLAS, LAPACK, Armadillo, and Eigen. I have decided to go with Eigen, mainly because the BLAS/LAPACK libraries have a quite scary interface/syntax, and because of this interview with the Eigen developers.
The Eigen syntax is quite nice if you come from an object-oriented background, and possibly most appealing is the fact that you do not need to build or compile any source when using Eigen; you simply copy some header files into your project, and you are ready to create and manipulate matrices.
The following code implements a version of Virtanen's algorithm in the Eigen C++ library (an appropriate number of iterations/updates is generally something like 300. You can also re-write this sort of algorithm to terminate when the reconstruction error between GW and V is low):
void factorizeMatrix(MatrixXf V_, MatrixXf W_, MatrixXf H_, int num_updates_) {
int xSize = V_.cols();
int ySize = V_.rows();
// Create our Gain matrix with randomized initial values
H_ = MatrixXf(num_sources_, xSize);
H_.setRandom();
H_ = H_.array().abs();
// Create our Spectra matrix with randomized initial values
W_ = MatrixXf(ySize, num_sources_);
W_.setRandom();
W_ = W_.array().abs();
// Create an identity matrix
MatrixXf ones = MatrixXf::Constant(xSize,ySize,1.0);
// Run the update rules for numUpdate iterations
for(int i = 0; i < num_updates_; i++) {
// update spectra
MatrixXf WH = (W_ * H_).array() + 0.00001;
MatrixXf numerator = (V_.array() / WH.array());
numerator = numerator * H_.transpose();
MatrixXf denominator = (H_ * ones).array() + 0.00001;
W_ = W_.array() * numerator.array();
W_ = W_.array() / denominator.transpose().array();
// update gains
WH = (W_ * H_).array() + 0.00001;
numerator = (V_.array() / WH.array());
numerator = W_.transpose() * numerator;
denominator = (ones * W_).array() + 0.00001;
H_ = H_.array() * numerator.array();
H_ = H_.array() / denominator.transpose().array();
}
// At this point, you have the relevant spectra and volume envelopes in W and H!
}
